🎯 Goal and Hypothesis
Goal: To build a tool that helps content appear in AI Overview results.
Hypothesis: AI Overview systems currently analyze millions of pages using a wide range of parameters. Some of these parameters are publicly known, while many remain undisclosed. Each parameter carries a certain weight and influences whether a page, piece of content, or brand appears in AI Overview.
The core idea is to develop a custom language model that learns directly from existing AI Overview outputs and improves with each iteration.
The model will be trained using the following input data:
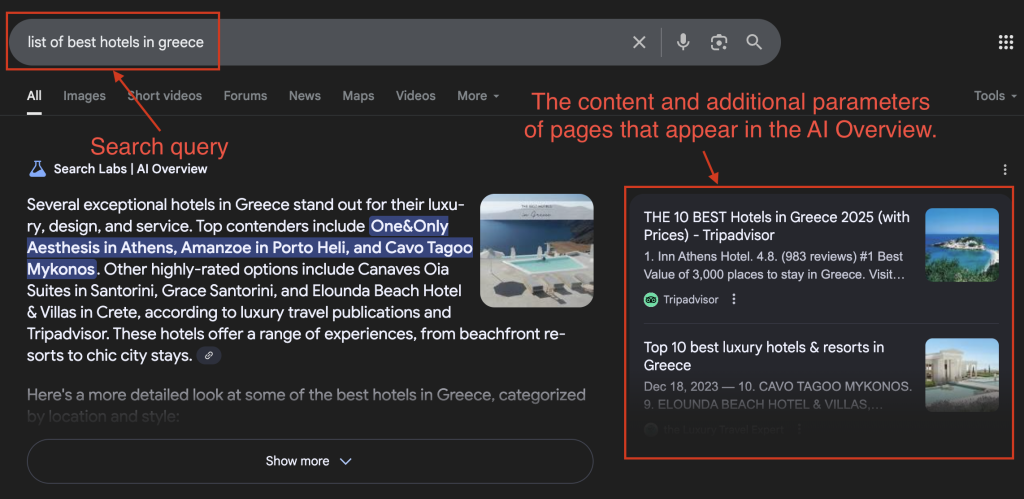
- A search query (e.g., list of best hotels in greece).
- The content and additional parameters of pages that appear in the AI Overview.
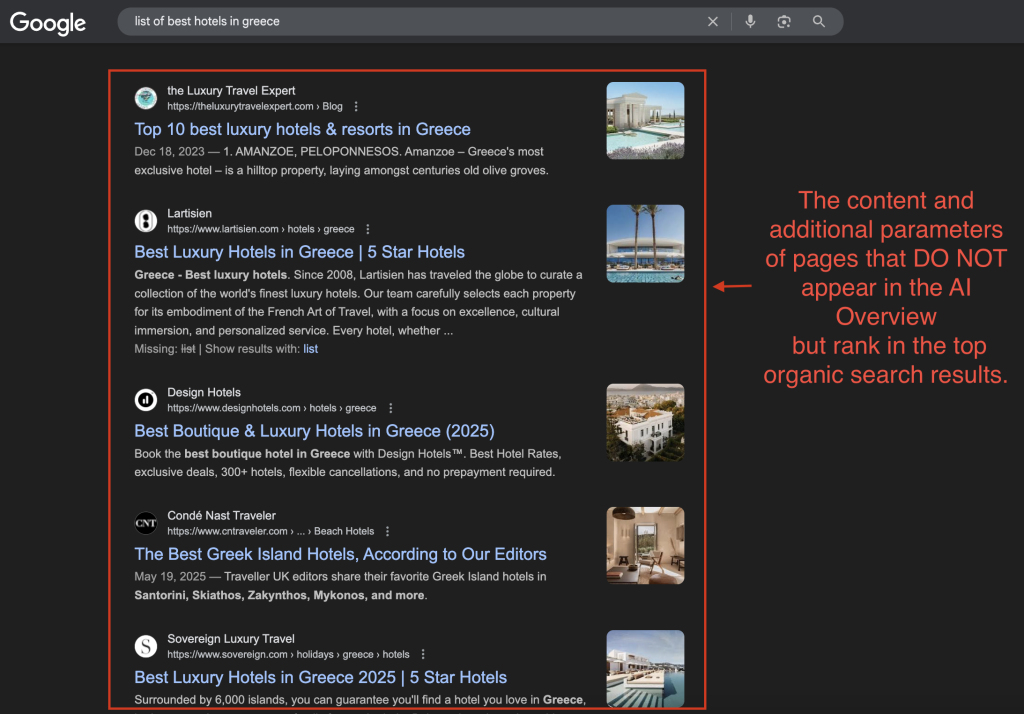
- The content and additional parameters of pages that do not appear in the AI Overview but rank in the top organic search results.
🔁 Methodology: PDCA Cycle
To ensure continuous improvement, I’m using the PDCA (Plan-Do-Check-Act) loop:
- Plan – Identify potential influencing factors and propose changes.
- Do – Implement those changes across selected test pages.
- Check – Analyze whether they impacted AI Overview visibility.
- Act – Refine model behavior and strategy based on results.
This will allow for fast experimentation and data-driven adjustments over time.
⚙️ Current Progress and What is Already Done
At the early stage, I’m focusing on two key parameters:
- Content – the quality and relevance of the text.
- Moz Domain Authority (DA) – a measure of a website’s credibility.
I’m building a language model based on BERT, which will analyze both content and Moz DA to determine which factors influence visibility in AI Overview and how significant each factor is.
I’ve prepared 15 search queries that currently trigger AI Overview results. These will serve as the initial training data for the model.
The model will receive:
- The query itself.
- The content and Moz DA of pages that appear in the AI Overview.
- The content and Moz DA of pages that do not appear in the AI Overview but rank in the top 10 organic search results.
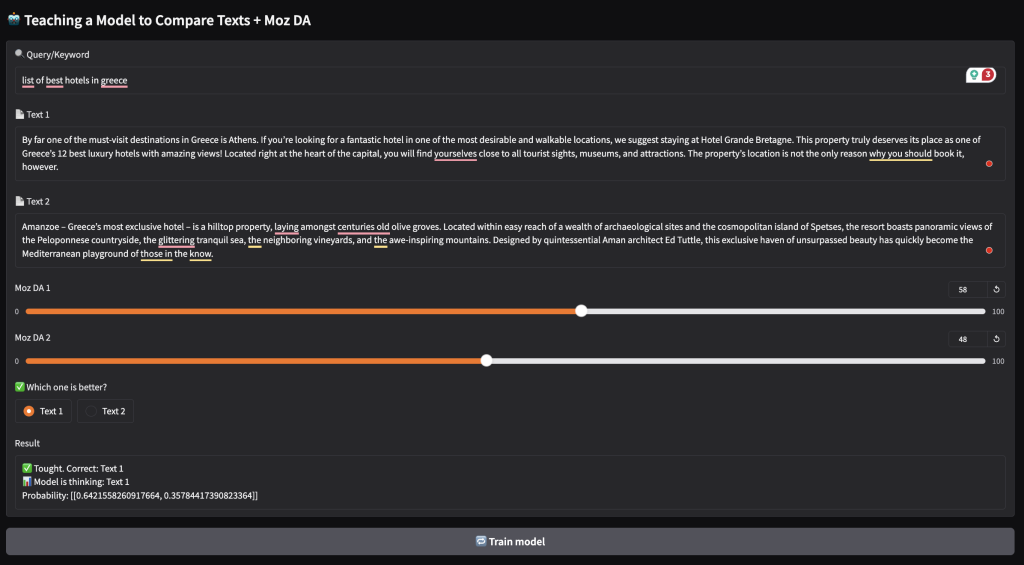
Based on this input, the model has learn to identify which features contribute to inclusion in AI Overview and estimate their importance.
Right now, the model predicts the likelihood of a page being featured in AI Overview. However, its accuracy is still too low.
🚀 What’s Next and How to Improve it
🧪 Expanding the Dataset
Currently, the model is trained on a small, manually collected dataset.
Manual collection is time-consuming, so the next major step is automation.
I plan to build a database containing:
- 1,000+ search queries
- The pages that appear in AI Overview for those queries
- The top 100 organic search results for each query that do not appear in AI Overview
This will significantly expand the dataset and help improve the model’s accuracy and generalization.
🔗 Using Existing Tools
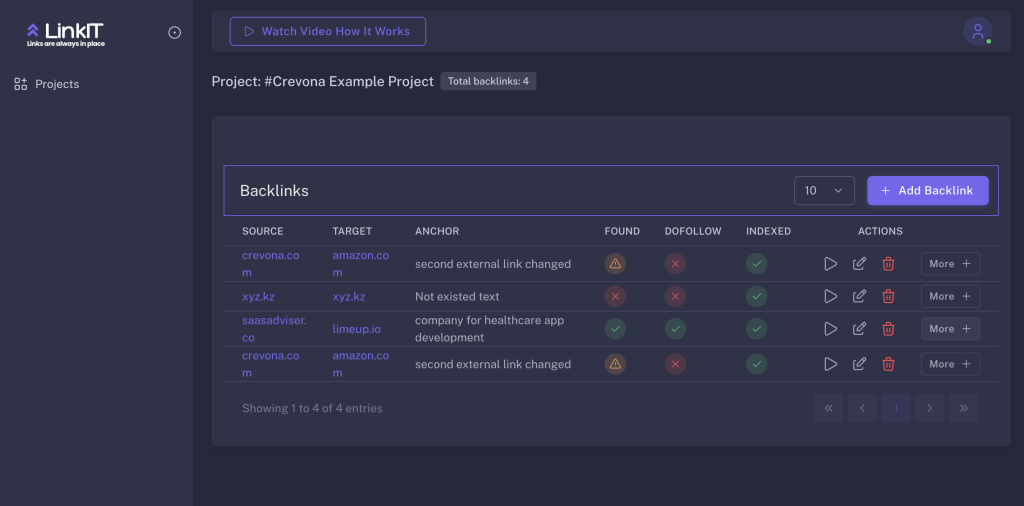
For content analysis, I will leverage an internal tool I previously developed for backlink content availability and analyse (https://linkit.crevona.com/):
This tool enables:
- In-depth content parsing
- Relevance scoring based on search intent
- Extraction of page structure and metadata
📈 Adding More Parameters
Once the dataset is scaled up, I plan to begin training the model on additional signals, such as:
- Structured data (schema.org)
- Core Web Vitals
- Page load speed
- Use of lists, tables, headings
- Keyword positioning
- Brand mentions and backlinks
- Others…
This will help the model assign dynamic weights to each factor based on real-world inclusion data, getting us closer to reverse-engineering what makes content AI Overview-worthy.
🤝 Let’s Collaborate
If you have ideas for additional parameters that could influence inclusion in AI Overview — whether technical, semantic, or related to authority signals — I’d love to hear your feedback.
Also, if you’re interested in joining the project as:
- a specialist (AI, SEO, data engineering, or UX),
- or an investor looking to support innovation at the intersection of SEO and AI,
feel free to reach out — I’m open to collaboration or to discuss it